단위테스트 (블라디미르 코리코프)
7장에서 다루는 내용
- 네 가지 코드 유형 알아보기
- 험블 객체 패턴 이해
- 가치 있는 테스트 작성
1. 리팩터링할 코드 식별하기
기반 코드를 리팩토링 하지 않고서는 테스트 스위트를 크게 개선할 수 없다.
* 테스트 스위트(test suite)
소프트웨어 프로그램을 테스트하여 특정 동작 집합이 있음을 보여주기 위한 테스트 케이스 모음
a collection of test cases that are intended to be used to test a software program to show that it has some specified set of behaviors.
테스트 코드와 제품 코드는 본질적으로 관련돼 있기 때문에 다른 방도는 없다.
1.1 코드의 네 가지 유형
모든 제품 코드는 2차원으로 분류할 수 있다.
- 복잡도 또는 도메인 유의성
- 협력자 수
코드 복잡도(code complexity)는 코드 내 의사 결정(분기) 지점수로 정의한다. 이 숫자가 클수록 복잡도는 더 높아진다.
도메인 유의성은 코드가 프로젝트의 문제 도메인에 대해 얼마나 의미 있는지를 나타낸다.
일반적으로 도메인 계층의 모든 코드는 최종 사용자의 목표와 직접적인 연관성이 있으므로 도메인 유의성이 높다. 반면에 유틸리티 코드는 그런 연관성이 없다.
복잡한 코드와 도메인 유의성을 갖는 코드가 단위 테스트에서 가장 이롭다. 해당 테스트가 회귀 방지에 뛰어나기 때문이다. 도메인 코드는 복잡할 필요가 없으며, 복잡한 코드는 도메인 유의성이 나타나지 않아도 테스트할 만하다. 이 두 요소는 서로 독립적이다. 예를 들어 주문 가격을 계산하는 메서드에 조건문이 없다면 순환 복잡도는 1이다. 그러나 이러한 메서드는 비즈니스에 중요한 기능이므로 테스트 하는 것이 중요하다.
| 순환 복잡도 계산법 순환 복잡도는 코드 복잡도를 설명하는데 사용된다. 순환 복잡도는 주어진 프로그램 또는 메서드의 분기 수를 나타낸다. 다음과 같이 계산한다. 1 + <분기점 수> 따라서 제어 흐름문(예: if 문 또는 조건부 루프)이 없는 메서드에서는 순환 복잡도가 1 + 0 = 1 이다. 이 지표에는 또 다른 의미가 있다. 메서드에서 시작부터 끝으로 가는 데 독립적인 경로의 수 또는 100% 분기 커버리지를 얻는 데 필요한 테스트의 수로 생각해볼 수 있다. 분기점 수는 관련된 가장 간단한 조건(predicate) 수로 계산한다. 예를 들어, IF 조건1 AND 조건2 THEN 은 IF 조건1 THEN IF 조건2 THEN과 같다. 따라서 복잡도는 1 + 2 = 3 이다. |
두 번째 차원은 클래스 또는 메서드가 가진 협력자 수다.
협력자는 가변 의존성이거나 프로세스 외부 의존성(또는 둘 다)이다.
협력자가 많은 코드는 테스트 비용이 많이 든다. 테스트 크기에 따라 달라지는 유지 보수성 지표 때문이다. 협력자를 예상되는 조건으로 두고 상태나 상호 작용을 확인하게끔 코드를 작성해야 한다. 협력자가 많을수록 테스트도 커진다.
협력자의 유형도 중요하다. 도메인 모델이라면 프로세스 외부 협력자를 사용하면 안 된다. 테스트에서 목 체계가 복잡하기 때문에 유지비가 더 든다. 또한 리팩터링 내성을 잘 지키려면 아주 신중하게 목을 사용해야 하는데, 애플리케이션 경계를 넘는 상호 작용을 검증하는 데만 사용해야 한다. 프로세스 외부 의존성을 가진 모든 통신은 도메인 계층 외부의 클래스에 위임하는 것이 좋다. 그러면 도메인 클래스는 프로세스 내부 의존성에서만 동작하게 된다.
암시적 협력자와 명시적 협력자 모두 이 숫자에 해당한다. 테스트 대상 시스템(SUT)이 협력자를 인수로 받거나 정적 메서드를 통해 암시적으로 참조해도 상관없지만, 테스트에서 이 협력자를 설정해야 한다. 반대로 불변 의존성(값 또는 값 객체 등)은 해당하지 않는다. 불변 의존성은 설정과 검증이 훨씬 쉽다.
코드 복잡도, 도메인 유의성, 협력자 수의 조합으로 만들 수 있는 코드 유형은
아래의 네 가지 코드 유형이다.
- 도메인 모델과 알고리즘 : 보통 복잡한 코드는 도메인 모델이지만, 100%는 아니다. 문제 도메인과 직접적으로 관련이 없는 복잡한 알고리즘이 있을 수 있다.
- 간단한 코드 : 매개변수가 없는 생성자와 한 줄 속성 같은 코드가 이에 해당된다. 협력자가 있는 경우가 거의 없고 복잡도나 도메인 유의성도 거의 없다.
- 컨트롤러 : 이 코드는 복잡하거나 비즈니스에 중요한 역할을 하는 것이 아니라 도메인 클래스와 외부 애플리케이션 같은 다른 구성 요소의 작업을 조정한다.
- 지나치게 복잡한 코드 : 이러한 코드는 두 가지 지표 모두 높다. 협력자가 많으며 복잡하거나 중요하다. 한가지 예로 덩치가 큰 컨트롤러(복잡한 작업을 어디에도 위임하지 않고 모든 것을 스스로 하는 컨트롤러)가 있다.
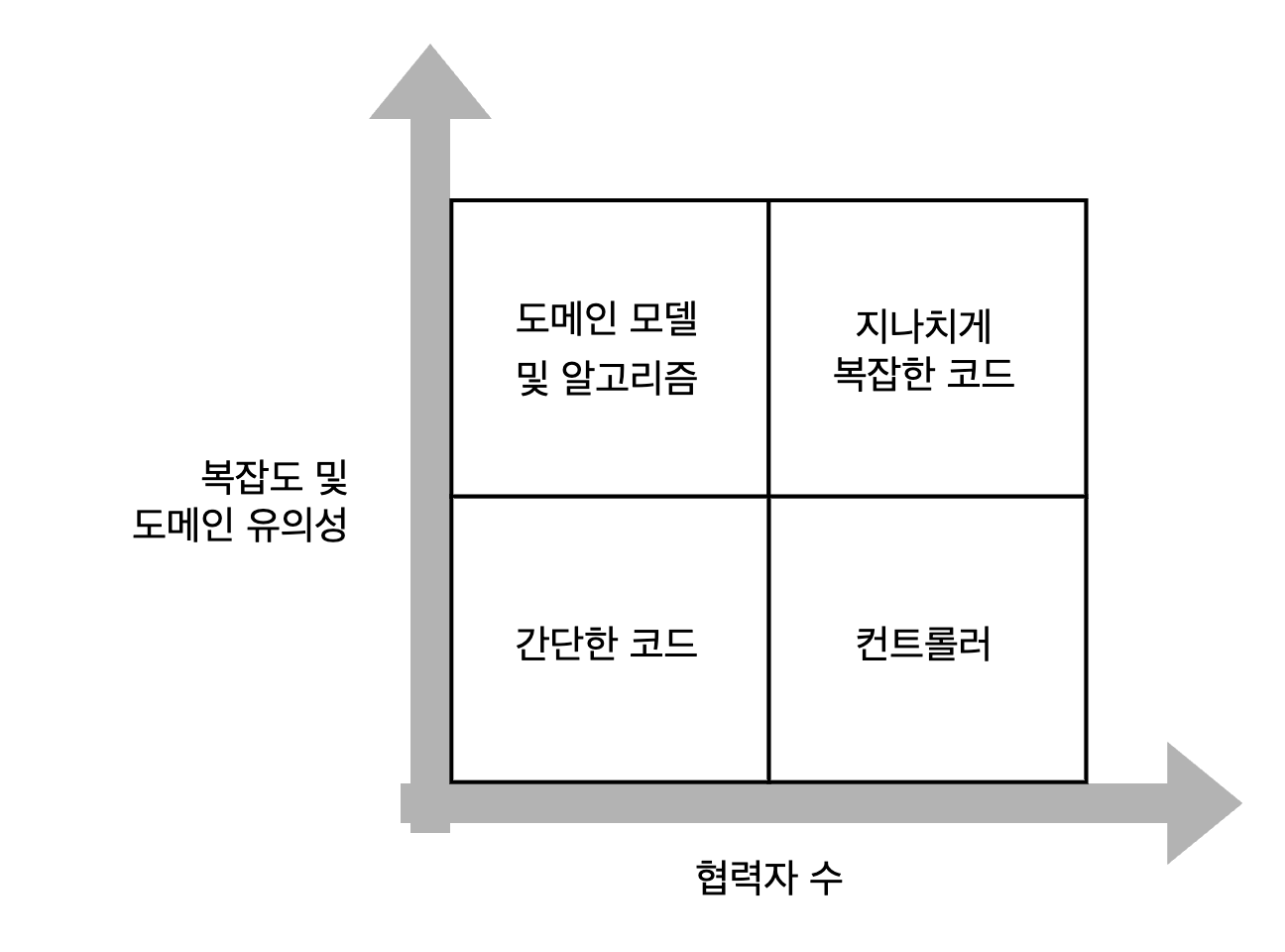
좌측 상단 사분면(도메인 모델 및 알고리즘)을 단위 테스트하면 노력 대비 가장 이롭다. 이러한 단위 테스트는 매우 가치 있고 저렴하다. 해당 코드가 복잡하거나 중요한 로직을 수행해서 테스트의 회귀 방지가 향상되기 때문에 가치 있다. 또한 코드에 협력자가 거의 없어서 (이상적으로는 완전히 없음) 테스트 유지비를 낮추기 때문에 저렴하다.
간단한 코드는 테스트할 필요가 전혀 없다. 이러한 테스트는 가치가 0에 가깝다.
컨트롤러의 경우, 포괄적인 통합테스트의 일부로서 간단히 테스트해야 한다.
가장 문제가 되는 코드 유형은 지나치게 복잡한 코드다. 단위 테스트가 어렵겠지만, 테스트 커버리지 없이 내버려두는 것은 너무 위험하다. 이러한 코드는 많은 사람이 단위 테스트로 어려움을 겪는 주요 원인 중 하나다.
때때로 실제 구현이 까다로울 수 있지만, 지나치게 복잡한 코드는 알고리즘과 컨트롤러라는 두 부분으로 나누는 것이 일반적이다.
코드가 더 중요해지거나 복잡해질수록 협력자는 더 적어야 한다.
지나치게 복잡한 코드를 피하고 도메인 모델과 알고리즘만 단위 테스트하는 것이 매우 가치 있고 유지 보수가 쉬운 테스트 스위트로 가는 길이다.
하지만 이 방법으로 테스트 커버리지를 100% 달성할 수 없으며, 이를 목표로 해서도 안된다. 목표는 각각의 테스트가 프로젝트 가치를 높이는 테스트 스위트다. 다른 모든 테스트를 리팩터링하거나 제거하라. 테스트 스위트의 크기를 부풀리지 말라.
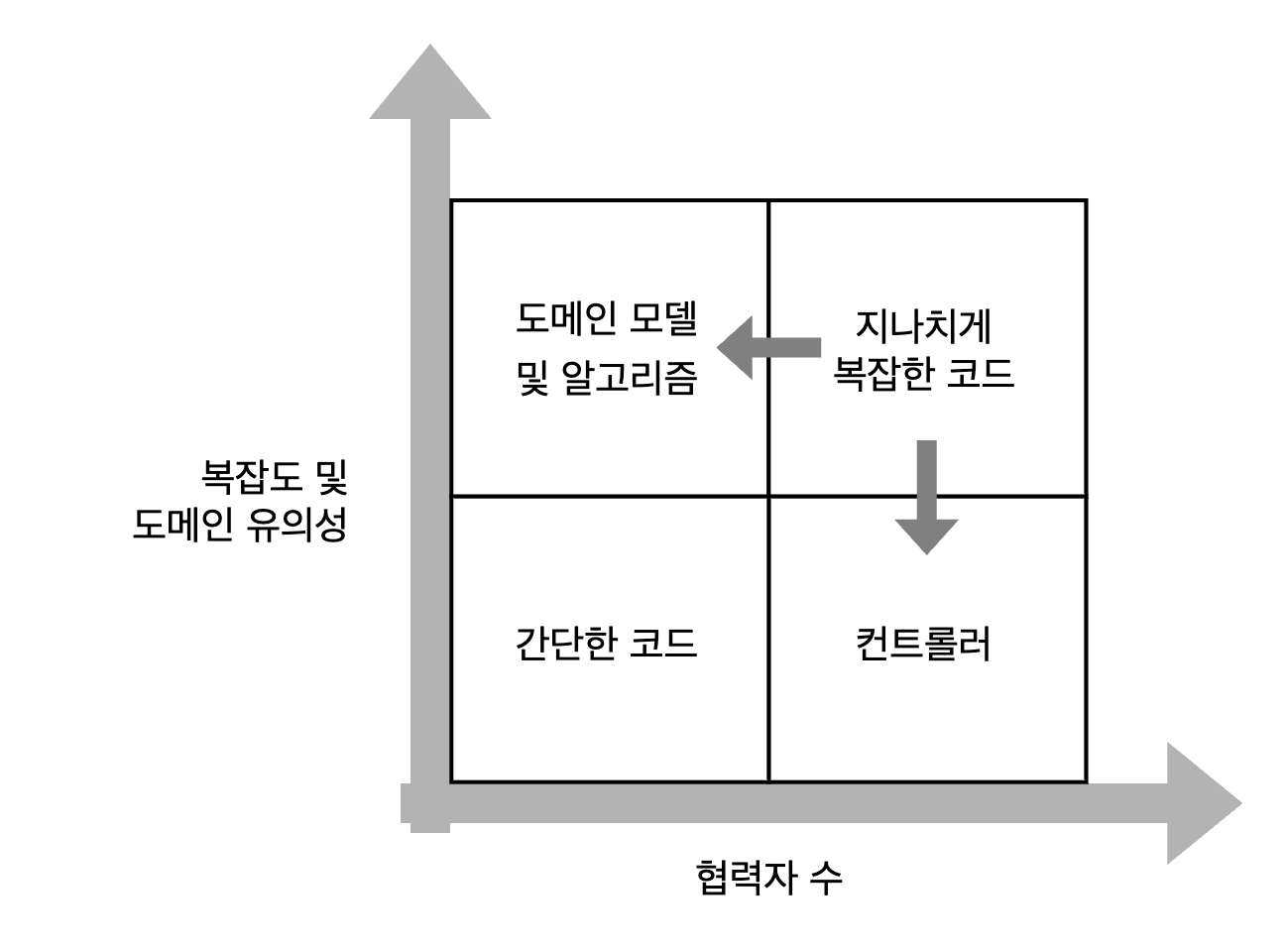
지나치게 복잡한 코드는 알고리즘과 컨트롤러로 나눠서 리팩터링하라. 이상적으로는 우측 상단 사분면에 속하는 코드가 있으면 안된다.
물론 지나치게 복잡한 코드를 제거하는 것은 말처럼 쉬운 일이 아니다.
1.2 험블 객체 패턴을 사용해 지나치게 복잡한 코드 분할하기
지나치게 복잡한 코드를 쪼개려면, 험블 객체 패턴을 써야 한다.
테스트 대상 코드의 로직을 테스트하려면, 테스트가 가능한 부분을 추출해야 한다. 결과적으로 코드는 테스트 가능한 부분을 둘러싼 얇은 험블 래퍼(humble wrapper)가 된다. 험블 래퍼가 테스트하기 어려운 의존성과 새로 추출된 구성 요소를 붙이지만, 자체적인 로직이 거의 없거나 전혀 없으므로 테스트할 필요가 없다
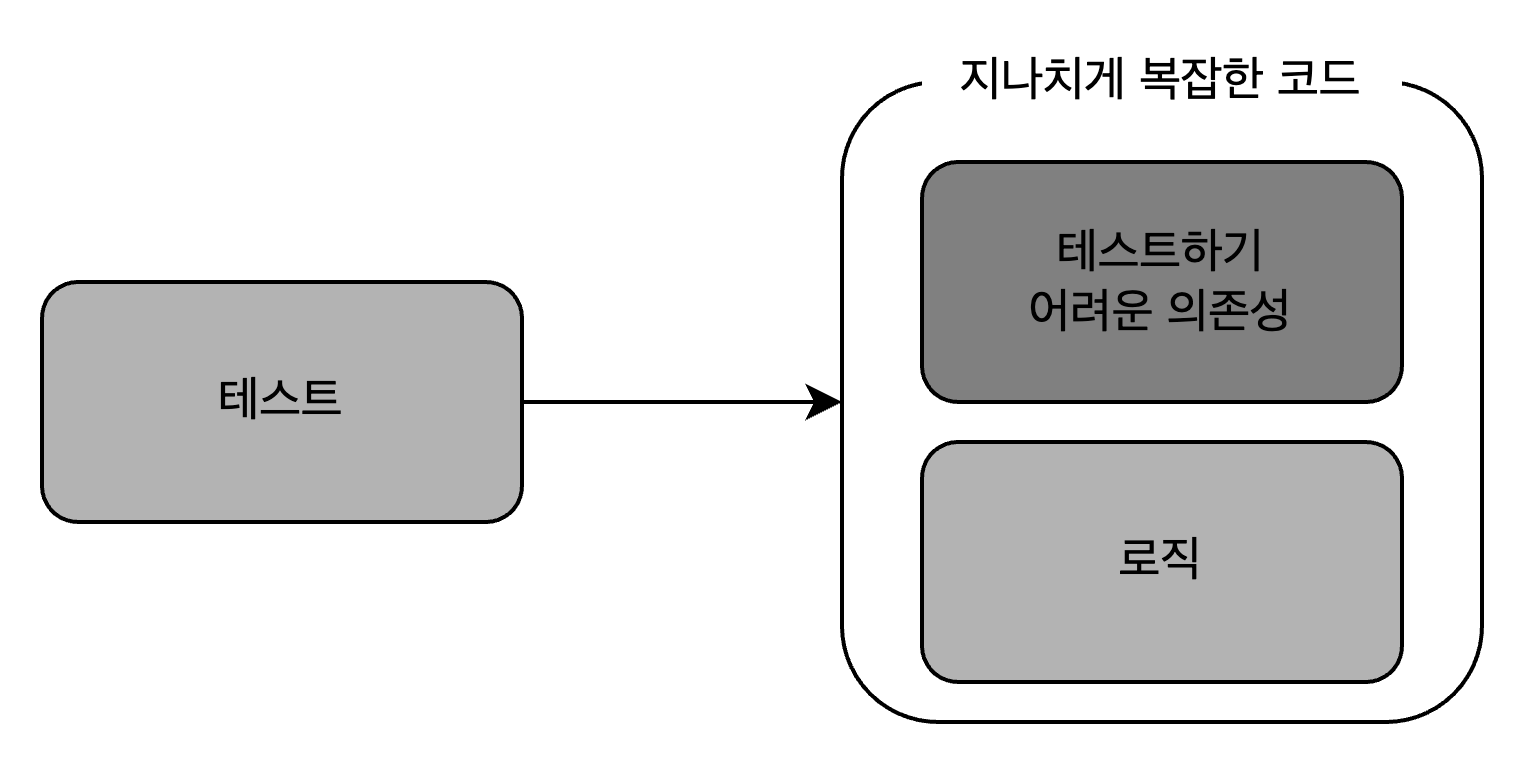

험블 객체 패턴은 지나치게 복잡한 코드에서 로직을 추출해 코드를 테스트 할 필요가 없도록 간단하게 만든다. 추출된 로직은 테스트하기 어려운 의존성에서 분리된 다른 클래스로 이동한다.
육각형 아키텍처와 함수형 아키텍처 모두 정확히 이 패턴을 구현한다.
험블 객체 패턴을 보는 또 다른 방법은 단일 책임 원칙(single responsibility principle)을 지키는 것이다. 이는 각 클래스가 단일한 책임만 가져야 한다는 원칙이다. 그러한 책임 중 하나로 늘 비즈니스 로직이 있는데, 이 패턴을 적용하면 비즈니스 로직을 거의 모든 것과 분리할 수 있다.
예를 들자면, 비즈니스 로직과 오케스트레이션(orchestration)을 분리하는 경우다.
코드의 깊이와 코드의 너비 관점에서 이 두 가지 책임을 생각해볼 수 있다. 코드가 깊거나(복잡하거나 중요함) 넓을(많은 협력자와 작동함) 수 있지만, 둘 다 가능하지는 않다.

컨트롤러는 많은 의존성을 조정하지만, 그 자체로 복잡하지는 않다. 도메인 클래스는 그 반대다.
다른 예로 MVP(Model-View-Presenter)와 MVC(Model-View-Controller) 패턴이 있다. 이 두 패턴은 비즈니스 로직(모델), UI 관심사(뷰) 그리고 모델과 뷰 사이의 조정(프리젠터 또는 컨트롤러)을 분리하는데 도움이 된다. 프리젠터와 컨트롤러 구성 요소는 험블 객체로, 뷰와 모델을 붙인다.
또 다른 예로 도메인 주도 설계(Domain Driven Design, DDD)에 나오는 집계 패턴(Aggregate pattern)이 있다. 그 목표 중 하나는 클래스를 클러스터(집계)로 묶어서 클래스 간 연결을 줄이는 것이다. 클래스는 해당 클러스트 내부에 강결합돼 있지만, 클러스터 자체는 느슨하게 결합돼 있다. 이러한 구조는 코드베이스의 총 통신 수를 줄인다. 그 결과, 연결이 줄어들고, 테스트 용이성이 향상된다.
비즈니스 로직과 오케스트레이션을 계속 분리해야 하는 이유는 테스트 용이성이 좋아져서 만이 아니다. 이렇게 분리하면 코드 복잡도를 해결할 수 있으며 이는 장기적으로 프로젝트 성장에도 중요한 역할을 한다.
'스터디-공부 > 테스트' 카테고리의 다른 글
| 7장 컨트롤러에서 조건부 로직 처리 (컨트롤러가 도메인의 세부사항을 모르도록 처리하자) (0) | 2023.08.08 |
|---|---|
| 7장 가치 있는 단위 테스트를 위한 리팩터링 (0) | 2023.07.28 |
| 6장 단위 테스트 스타일 – 함수형 아키텍처의 단점 이해 + 6장 요약 (0) | 2023.07.15 |
| 6장 단위 테스트 스타일 – 함수형 아키텍처와 출력 기반 테스트로의 전환 (0) | 2023.07.15 |
| 6장 단위 테스트 스타일 - 함수형 아키텍처 (0) | 2023.07.13 |




댓글