가상 면접 사례로 배우는 대규모 시스템 설계 기초 - System Design Interview
1장 사용자 수에 따른 규모 확장성 : 어떻게 수백만 사용자를 지원하는 시스템을 설계할 것인가.
1장 사용자 수에 따른 규모 확장성 (1) - 웹서버, 데이터베이스, 로드밸런스
1장 사용자 수에 따른 규모 확장성 (2) – 데이터베이스 다중화
1장 사용자 수에 따른 규모 확장성 (3) – 캐시, CDN
1장 사용자 수에 따른 규모 확장성 (4) - 무상태 웹 계층, 데이터 센터
에서 이어지는 글입니다.
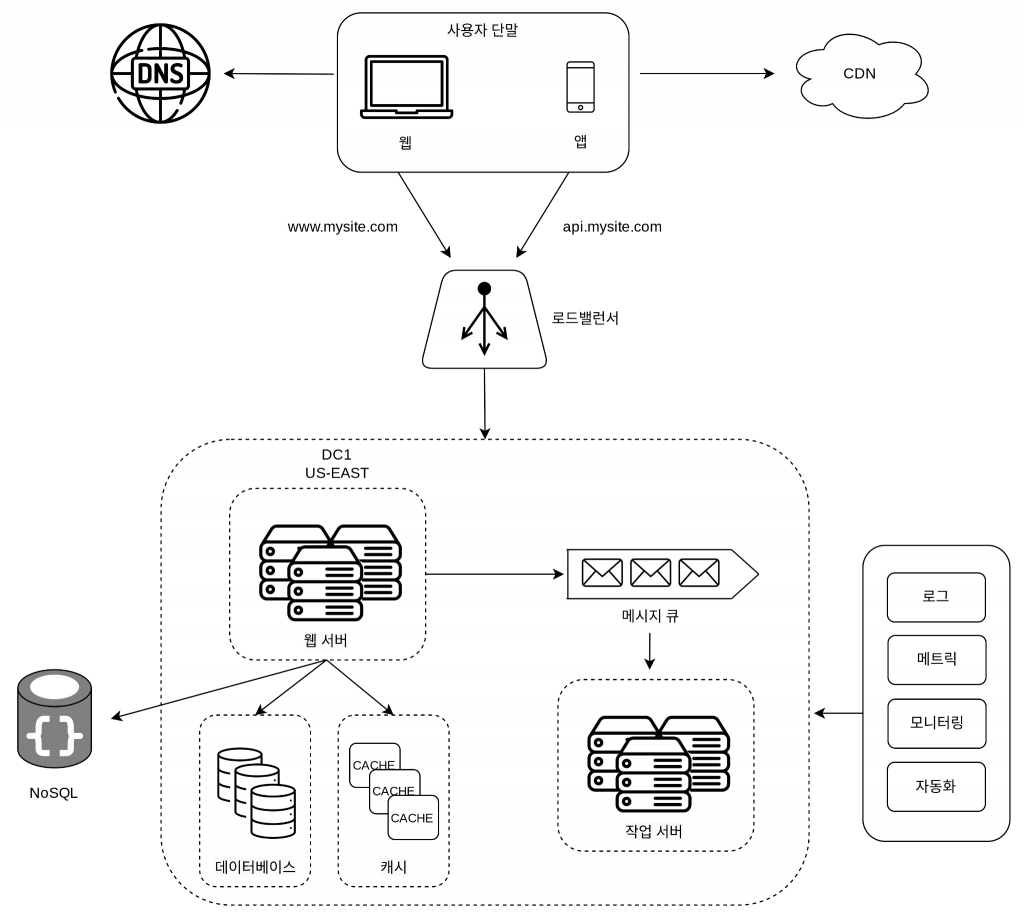
메시지 큐
메시지 큐는 메시지의 무손실(durability, 즉 메시지 큐에 일단 보관된 메시지는 소비자가 꺼낼 때까지 안전히 보관된다는 특성)을 보장하는, 비동기 통신을 지원하는 컴포넌트이다. 메시지의 버퍼 역할을 하며, 비동기적으로 전송한다.

메시지 큐를 사용하면 서비스 또는 서버 간 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 좋다. 생산자는 소비자가 다운되어 있어도 메시지를 발행할 수 있고, 소비자는 생산자 서비스가 다운되어도 메시지를 수신할 수 있다.
그러면 메시지 큐 가 다운되면…?
역시나 답 없어짐. 따라서 메시지 큐도 다운되지 않도록 잘 모니터링 해야함.
로그, 메트릭 그리고 자동화
로그
에러 로그를 모니터링하는 것은 중요하다. 시스템의 오류와 문제들을 보다 쉽게 찾아낼 수 있도록 하기 때문이다.
서버 단위로 모니터링 할 수도 있지만 단일 서비스로 모아주는 도구를 활용하면 더 편리하게 검색하고 조회할 수 있다.
메트릭
메트릭(metric)은 시스템의 성능, 가용성, 안정성 등과 같은 중요한 측면을 측정하는 데 사용되는 측정 항목이다.
메트릭을 통해
- 사업 현황과 관련한 유용한 정보를 얻을 수 있음.
- 시스템의 현재 상태를 파악할 수 있음.
유용한 메트릭들
호스트 단위 메트릭: CPU, 메모리, 디스크 I/O
종합(aggregated) 메트릭: 데이터베이스 계층의 성능, 캐시 계층의 성능
핵심 비지니스 메트릭: 일별 능동 사용자(daily active user), 수익(revenue), 재방문(retention)
자동화
생산성을 높일 수 있도록 도와줌. 지속적 통합 도구를 통해 빌드, 테스트, 배포 등의 절차를 자동화 할 수 있음.
여기까지의 시스템 구성도
데이터베이스의 규모 확장
데이터베이스의 규모를 확장하는 두가지 방법 : 마찬가지로 수직적 확장, 수평적 확장
데이터베이스의 수평적 확장은 샤딩이라고도 부른다.
샤딩은 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술이다.
모든 샤드는 같은 스키마를 가지고 있지만 샤드에 보관되는 데이터 사이에는 중복이 없다.

샤딩 전략을 구현할 때 고려해야할 가장 중요한 점
샤딩 전략을 구현할 때 고려해야할 가장 중요한 것은 샤딩 키를 어떻게 정하느냐 하는 것이다.
* 샤딩 키는 파티션 키(partition key) 라고도 함
샤딩 키는 하나 이상의 컬럼을 이용하여 구성된다.
샤딩 키를 통해 어떤 데이터베이스에 질의를 보낼지 정해지게 된다.
따라서 샤딩 키를 정할때는 데이터를 고르게 분할 할 수 있도록 하는 게 가장 중요하다.
샤딩을 이용할 경우 마주칠 수 있는 문제
- 데이터 재 샤딩
데이터가 너무 많아져서 추가적인 샤드가 필요할 때, 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치 해야한다.
- 유명인사(celebrity) 문제
특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제.
자주 질의되는 데이터를 한 샤드에 몰리는 것을 방지해야한다.
- 조인과 비정규화(join and de-normalization)
데이터가 여러 서버로 나눠지기 때문에 조인이 어려워진다.
이를 해결하는 한 가지 방법은 데이터베이스를 비정규화 하는 것이다.
* 비정규화 : 데이터를 중복 저장하여 데이터를 더 빠르게 검색하거나 처리하는 방식
관계형 데이터베이스가 요구되지 않는 기능은 NoSQL로 이전하는게 좋음.
1장 요약 : 백만 사용자, 그리고 그 이상
시스템 규모를 확장하는 것은 지속적이고 반복적(iterative)인 과정이다.
1장에서 나온기법들 정리
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 한 많은 데이터를 개시할 것
- 여러 데이터 센터를 지원할 것
- 정적 콘텐츠는 CDN을 통해 서비스할 것
- 데이터 계층은 샤딩을 통해 그 규모를 확장할 것
- 각 계층은 독립적 서비스로 분할할 것
- 시스템은 지속적으로 모니터링하고, 자동화 도구들을 활용할 것
Q. 마스터-슬레이브 와 샤딩 중 어떤 상황에서 어떤 것을 선택하는게 좋을까?
'스터디-공부 > 시스템 디자인' 카테고리의 다른 글
| 3장 시스템 설계 면접 공략법 (1) | 2023.05.10 |
|---|---|
| 2장 개략적인 규모 추정(back-of-the-envelope estimation) (0) | 2023.05.05 |
| 1장 사용자 수에 따른 규모 확장성 (4) - 무상태 웹 계층, 데이터 센터 (0) | 2023.05.03 |
| 1장 사용자 수에 따른 규모 확장성 (3) - 캐시, CDN (0) | 2023.05.02 |
| 1장 사용자 수에 따른 규모 확장성 (2) - 데이터베이스 다중화 (0) | 2023.05.02 |




댓글